









Introduction
Businesses rely on data scraping for all kinds of insights—whether it’s e-commerce teams watching rival prices, financial firms tracking market swings, retailers checking stock levels, or marketing groups gauging customer sentiment. To meet these needs, the market now offers everything from simple, no-code scraping apps to developer-oriented libraries like Beautiful Soup and Scrapy, plus advanced, cloud-based AI services that automatically solve CAPTCHAs and render JavaScript-heavy pages. You can pick a ready-made service or build an in-house solution if you have the expertise.
- Maintenance overhead: Homegrown scrapers deliver full control but require frequent updates as target sites evolve.
- Time to value: Commercial platforms can be deployed quickly but may not accommodate every bespoke workflow.
- Compliance & security: Respecting robots.txt policies, rate limits and applicable regulations is essential—and often challenging.
- Scalability: Managing sudden spikes in data volume or crawling hundreds of sites demands a robust, distributed infrastructure.
In this article, we’ll walk through the top scraping solutions on the market, weigh the pros and cons of building your own versus buying a ready-made platform, and show how PinoByte brings together developer flexibility, enterprise-grade reliability, and AI-powered data cleaning into one seamless package.
// Octoparse //
Let’s kick off with Octoparse—a no-code scraper that even non-techies can master in minutes. You simply load a page, click on the bits of data you want (login forms, dropdowns, endless scrolls or AJAX-loaded content—all handled automatically), and hit “Go.” In the cloud, Octoparse quietly swaps IPs and proxies to dodge blocks, lets you set up one-time or recurring runs, and will retry from the last successful step if a task fails. When it’s done, grab your data as CSV, Excel, HTML or TXT—or hook straight into their REST API and feed results right into your dashboards. With its intuitive interface, robust anti-blocking measures, and flexible output options, Octoparse makes web data extraction seamless for many projects.
Easy to use? Sure. But for high-volume use cases, most ready-to-use solutions including Octoparse are slow. Typically, when you trigger a parsing flow, they spin up a new Docker instance (or similar environment) and begin crawling the required pages asynchronously. You then have to fetch the results asynchronously as well, which can be inefficient and time-consuming.
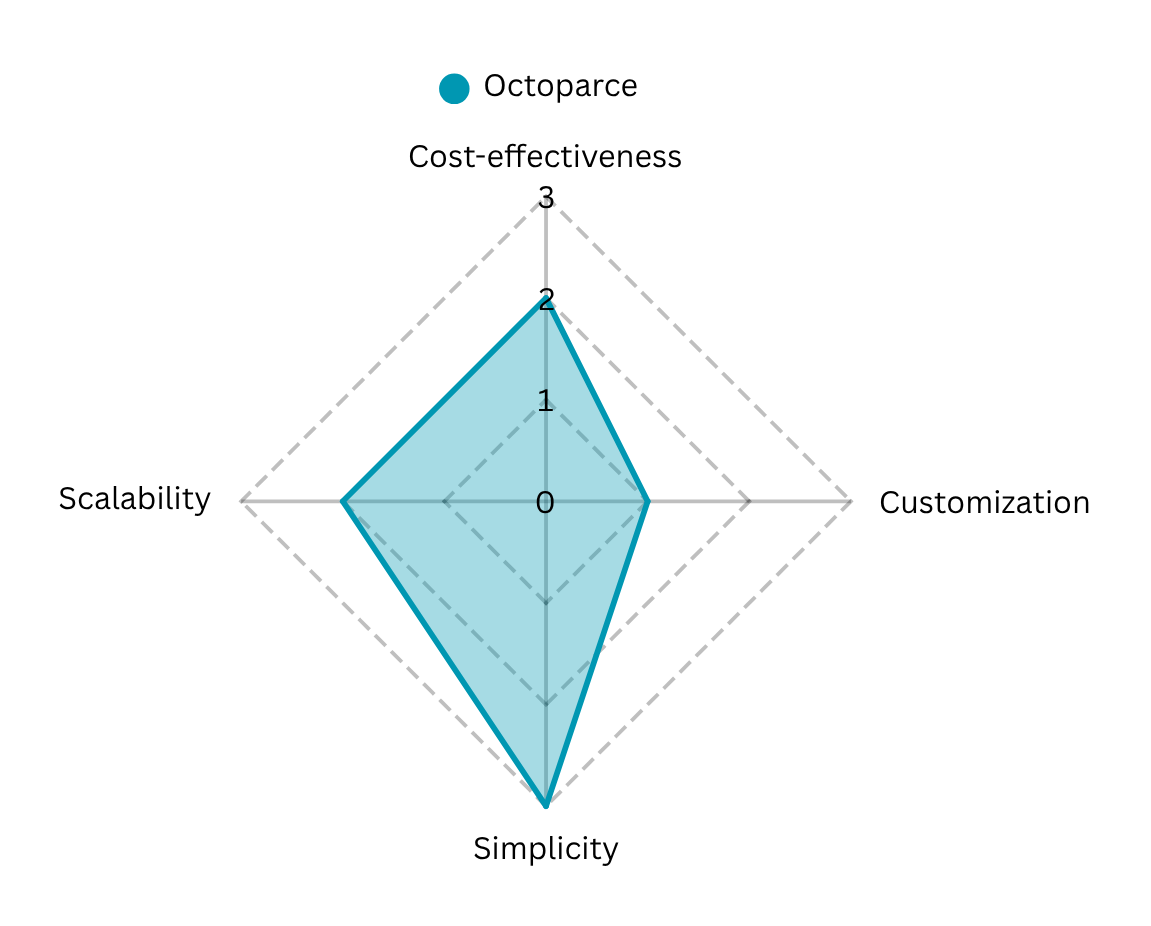
Advantages:
- Drag-and-drop setup and automatic field detection mean you’re up and running in minutes.
- You can handle logins, dropdowns, infinite scroll and AJAX-loaded elements without a single line of code.
Limitations:
- Hundreds of concurrent crawls can strain even the Enterprise Plan—extra infrastructure may be needed.
- Extremely bespoke extraction logic can exceed what the visual builder natively supports, forcing workarounds.
- Advanced proxy pools, high concurrency and AI-based CAPTCHA solving all sit behind pricier tiers.
//ParseHub//
ParseHub is another popular no-code scraper but this time you can install it on Windows, macOS, or Linux (with a free starter tier). Its visual interface lets you click to select the data you need, while built-in tools cover pagination, task scheduling, and API access for fetching results. You can even hook into webhooks for instant data delivery, making it ideal for teams who want automated scraping without any coding.
This simplicity comes at a price. When choosing ParseHub or a similar tool, keep in mind that most ready-to-use scraping solutions limit the number of requests included in your subscription. More importantly, even on business or premium plans, these limits are so low that for applications requiring 100,000, 200,000, or 300,000 requests per day, it’s simply impossible to use these services effectively.
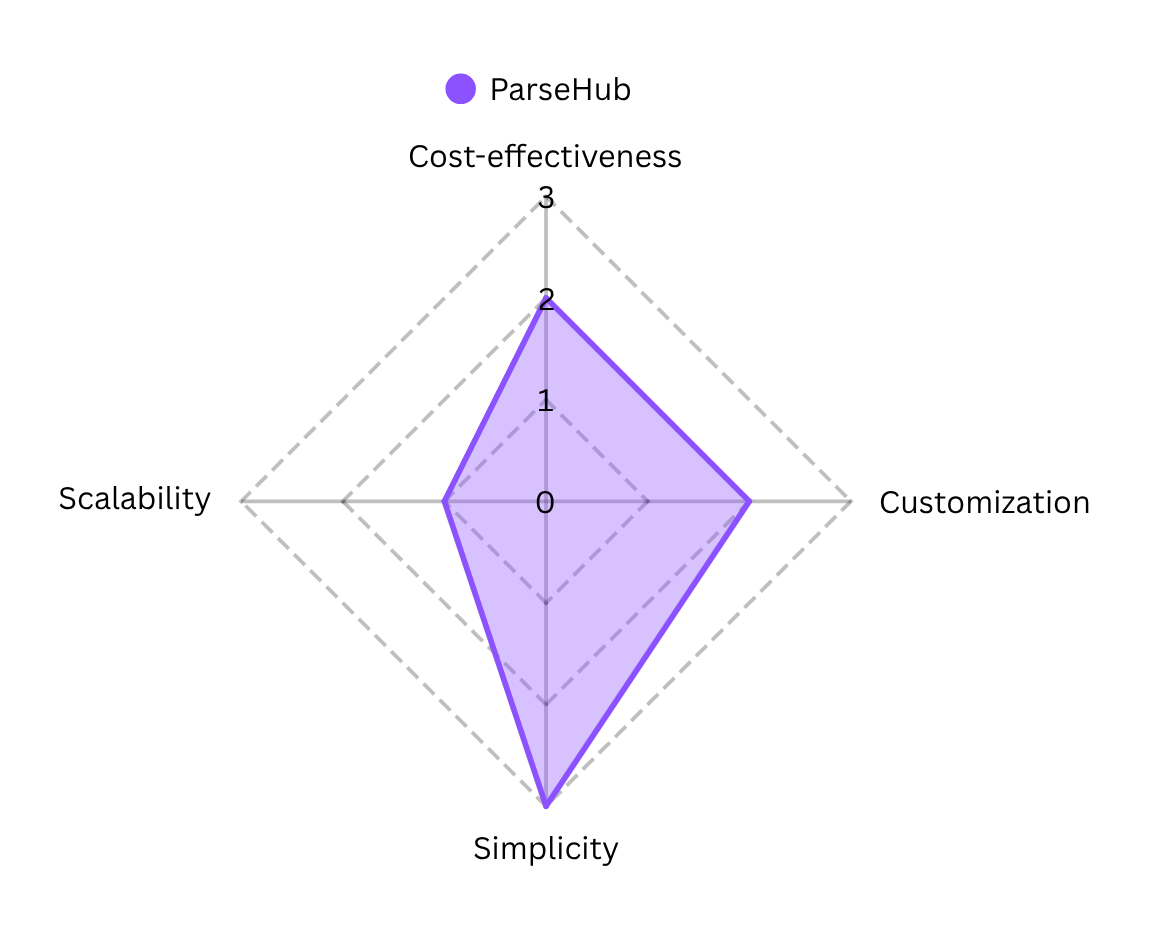
Advantages:
- ParseHub runs on Windows, macOS, and Linux, so you can build and validate workflows locally before moving to cloud-based execution.
- You can schedule jobs, leverage a full REST API, and trigger webhooks on completion—no manual polling required.
Limitations:
- Entry plans restrict threads and pages per run, which can slow high-volume or time-sensitive extractions.
- Advanced logic (nested loops, conditional steps) can get tricky in the visual editor, requiring practice.
- As ParseHub lacks built-in CAPTCHA handling you’ll need external solutions or manual steps to bypass CAPTCHA-protected pages.
//Diffbot AI-Powered API//
Diffbot is an AI-driven service that uses machine learning and computer vision to extract structured data from web pages. It automatically identifies page elements (articles, products, discussions, etc.) and returns them in a structured format. Diffbot provides public APIs and even a global Knowledge Graph of over 2 billion entities, enabling enterprises to “read” the web like a database. This makes Diffbot well-suited for organizations needing large-scale, automated extraction and semantic understanding of web content with minimal manual setup.
Advantages:
- Eliminates manual scraping rules by using computer vision and ML to “see” and interpret pages, reducing setup time and maintenance compared to traditional scrapers.
- Offers one of the largest commercial Web knowledge graphs, with over 2 billion entities and ten trillion facts—ideal for semantic search, enrichment, and analytics.
Limitations:
- Pricing is consumption-driven and can be unpredictable; overages are billed at the per-credit rate, making budgeting challenging for high-volume or variable workload
- The AI decides how to interpret a page—if it misclassifies content, you have limited ability to tweak its “understanding.”
API calls consume credits and are subject to rate limits; hitting these thresholds can result in 429 errors or delayed data retrieval until quotas reset. Real-time page analysis via an external API can be slower than an in-house scraper hitting your own proxies.
//Custom Solutions using Beautiful Soup//
Now let’s move into the “build” part. Today’s developer toolkit is vast, but when it comes to pure HTML/XML parsing, Beautiful Soup remains the go-to Python library. Unlike the above tools, it requires programming skills, but it offers great flexibility. Beautiful Soup can handle poorly formed or complex web pages and lets developers use Python logic to navigate and extract data from the DOM. Its extensive documentation and large community mean it’s relatively easy to learn. In short, Beautiful Soup is ideal for developers who want a free, scriptable tool to perform custom parsing tasks.
Advantages:
- Beautiful Soup is fully open source. The source code is publicly hosted so you can review, contribute to, or fork the project under the terms of its open-source license.
- Beautiful Soup’s API is designed with Pythonic idioms that make DOM traversal and data extraction intuitive, and it integrates seamlessly with other libraries making such solutions highly customizable.
Limitations:
- Because it’s a library rather than a GUI tool, you must write, debug, and maintain Python scripts for every scraper you build.
- Beautiful Soup cannot execute JavaScript; to scrape dynamic content, you need external headless browsers or rendering tools, adding complexity.
- Whenever a website’s structure changes, your parsing logic can break, requiring manual updates to selectors and traversal code.
//PinoByte’s Data Scraping as a Service//
When off-the-shelf tools aren’t enough, and building entirely in-house is costly and time-consuming, PinoByte offers Data Scraping as a Service as an ideal middle ground.
In many cases, crawling data from the source can be achieved in different ways. Ready-to-go solutions usually charge you for each successfully parsed page. However, if you decide to use a proxy instead, your proxy provider will most likely charge you based on the amount of downloaded traffic, not per successfully parsed page. As a result, using a proxy can sometimes be 10x less expensive and much faster than using credits from web scraping APIs.
We take a broader view of each project and refer to this as “fallback logic.” The idea is simple: always have alternative ways to achieve the same result in your parsing pipeline. For example, if you want to scrape e-commerce product data, you might implement several fallback options:
- Custom Scraper: Parse the HTML page directly. Often, you’ll find the same data in different tags, or even as plain JSON embedded in the page, giving you multiple options to extract the required values.
- Proxy Chains: Use a sequence of different proxies, starting from cloud-based to mobile proxies, to reduce costs and improve reliability.
- Web Scraping APIs: As another fallback, leverage ready-made web scraping APIs if other methods fail.
We believe monitoring, resilience, and a robust backup strategy aren’t optional add-ons—they’re the foundation of any truly reliable scraping solution.
Choosing PinoByte you get a fully customized, enterprise-grade parsing solution tailored to your business’s most complex demands—hosted in the cloud or on-premises—without the burden of maintaining a full in-house infrastructure.
Advantages:
- From requirements gathering through QA and maintenance, PinoByte’s team handles all phases—minimizing your internal project overhead.
- Every integration point is hand-crafted reducing your risk and integration headaches.
- Every parsing pipeline is designed from the ground up to match the customer’s data sources, business logic, and compliance requirements.
- Guaranteed uptime, priority issue resolution, and regular health checks come standard.
- Clients can choose cloud hosting for rapid scalability or on-premises installation for maximum security and data control.
Limitations:
- Major changes to project requirements after development starts may require additional scoping, testing and cost adjustments.
Curious to see how this works in practice? Check out our detailed Multi-Channel Auto Aggregator success story, or better yet, contact us to discuss how we can tailor a parsing solution specifically for your business.






